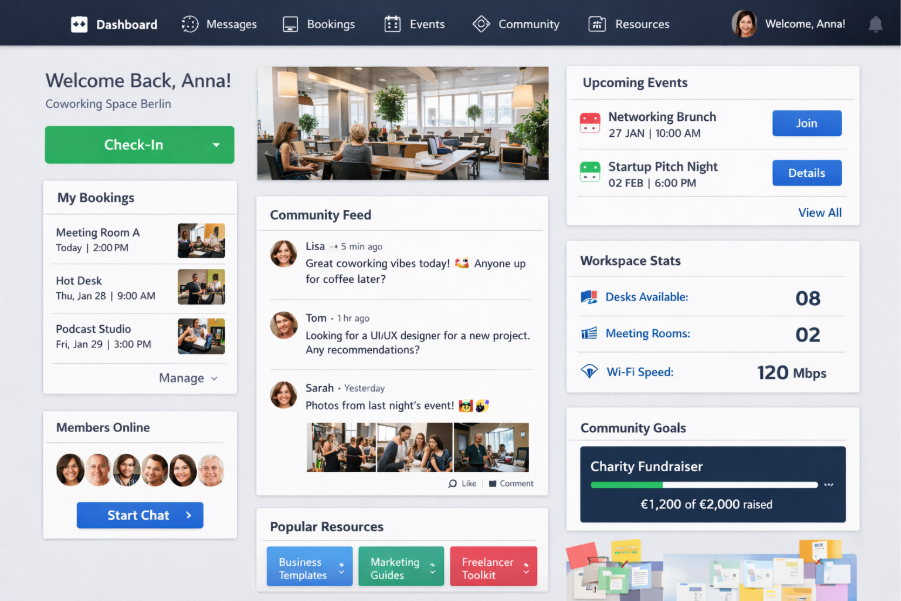
Im letzten Meetup der Community für Datenkompetenz hat Basti Reh uns einen Einblick in den Entstehungsprozess des internen zedita Dashboards gegeben.
Er selbst hat es als ein Wochenendprojekt bezeichnet, dass man auch ohne große Programmierkenntnisse mithilfe von Vibe-Coding umsetzen kann. Inspiriert hat ihn ein Youtube Video von Prof. Dries Faems, in dem dieser in rund 15 Minuten erläutert, wie man so ein Projekt aufziehen kann. Vibe-Coding bezeichnet die Programmierung mithilfe einer KI – genau gesagt, mithilfe eines Large Language Models (LLM). Dafür schreibt man die Anweisungen in einfachen Worten als Prompt und die KI gibt den zugehörigen Code aus.
Bei der Entwicklung des Dashboards setzt Basti auf das folgenden Technologie-Stack: Cursor (Entwicklungsumgebung), Claude (LLM) und Streamlit (Python Framework für Daten-Applikationen). Ist das Dashboard erstmal aufgesetzt, ist die Entwicklung der Inhalte eher ein iterativer Prozess. Daten müssen ausfindig gemacht und über Schnittstellen angebunden werden. Sinnvolle Kennzahlen müssen entwickelt und durch die Zahlen quantifizierbar gemacht werden. Auf dem Dashboard müssen die Kennzahlen dann auch noch irgendwie dargestellt werden. Das ist gar nicht so einfach, insbesondere da auch immer berücksichtigt werden muss, für wen und zu welchem Zweck die Informationen auf dem Dashboard aufbereitet werden sollen.
Basti hat unter anderem Ansätze für die Messung der prozentualen Raumauslastung im zedita, der Buchungen von Veranstaltungen und der Zählung von Followern und Reaktionen auf verschiedenen Social Media Kanälen gezeigt. Schon die Messung der prozentualen Raumauslastung hat gezeigt, dass bei der Entwicklung von Kennzahlen (oder auch Key Performance Indicators (KPIs)) der Teufel im Detail steckt. Denn was soll denn hier die Basis für die prozentuale Auslastung sein? 24/7? Werktags von 9 bis 18 Uhr? Was ist, wenn dann mal ein Raum am Wochenende gebucht wird? Kommt nicht ständig vor, aber doch ab und zu mal. Spätestens danach war allen klar, dass Kennzahlen immer nur im Kontext interpretiert werden können und dass dafür teilweise bestimmte Informationen über die Konstruktion der Kennzahlen zur Verfügung stehen müssen.
Danach war Raum für Diskussion und Gespräche rund um das Thema Dashboards und sinnvolle KPIs. Wir haben festgestellt, dass es bei der KI unterstützen Erstellung von Dashboards mehrere Punkte zu beachten gibt. Unter anderem sollte die Berechnung der Kennzahlen überprüft werden. In Bastis Fall ist es einfach möglich, sich den Python-Code anzuschauen, auf dessen Basis die einzelnen Kennzahlen berechnet werden. Sollte ein LLM für die Berechnung von Kennzahlen verantwortlich sein, ist Vorsicht geboten, denn das Rechnen gehört nicht zu deren großen Stärken. Da die Berechnung im Fall eines LLMs nicht nachvollzogen werden kann (Stichwort Blackbox-Algorithmus), sollten die Kennzahlen stichprobenweise mit Rechnungen per Hand (oder mit einer Statistiksoftware) abgeglichen werden. Nur dann kann man sich sicher sein, dass gerechnet wurde, was gerechnet werden sollte. Ein weiteres Problem stellt der Datenschutz dar. Welche Daten dürfen an die KI weitergeben und von ihr verarbeitet werden? Wenn das Dashboard nicht lokal gehostet wird, sondern online abrufbar ist, stellt sich auch die Frage, ob die Daten auf den entsprechenden Servern überhaupt gespeichert werden dürfen. Als weiterer kritischer Punkt wurde angemerkt, dass die KI, die einem bei der Erstellung des Dashboards unterstützt hat, nun natürlich auch genau weiß, wie das Dashboard aussieht. Ob das ein relevanter Nachtteil ist oder nicht, hängt wohl davon ab, ob das Dashboard als ein Service verkauft oder als Wettbewerbsvorteil im Unternehmen gesehen wird.
Im März wollen wir uns etwas genauer mit dem Thema sinnvolle Kennzahlen und grafische Aufbereitung dieser beschäftigen. Meldet euch gern bei mir, falls ihr diesbezüglich ganz konkrete Fragen oder auch einen Use Case habt, den ihr gern im Meetup mit der Community besprechen würdet.
Eure Carina
